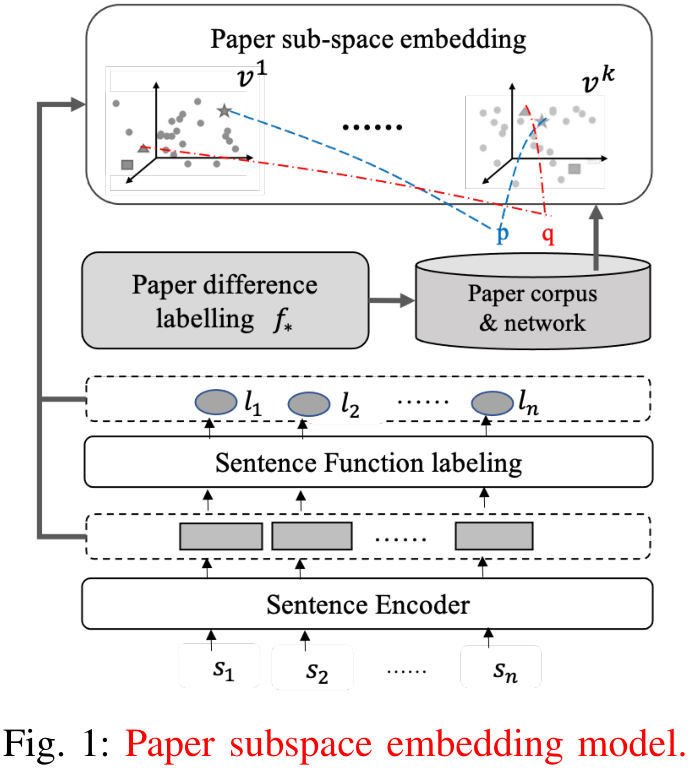
摘要——由于每年都有大量的学术论文发表,因此能够推荐高质量的论文是至关重要的。论文评价的典型方法是利用文献信息,但这并不适用于论文。针对这一缺陷,本文从一个新颖的视角来分析一篇论文与其他论文的内容差异与其创新之处。由于创新往往具有特定领域的特征和形式,我们引入了子空间的概念来描述论文内容中公认的方面,即背景、方法和结果。通过形式化一组专家规则来标注论文之间的差异,并在此基础上提出了一个孪生网络来学习论文在不同子空间中的嵌入情况。一系列的实证研究表明,在这些子空间中,论文影响力与其差异之间存在着明显的相关性。研究结果还显示了不同学科创新的特点。为了考虑学术网络信息对论文推荐的影响,我们提出了图卷积神经网络方法,将论文内容与其他相关元素相结合,采用用户兴趣和学术影响力不对称的建模方法。在真实数据集上的实验结果表明,该方法比其他基线方法更有效。为了展示本文方法建模非对称的用户兴趣和学术影响力的必要性,我们针对学科分类和专家特征做了进一步分析。最后,在专利数据集上验证了该方法的可重用性。结果表明,该方法同样适用于低资源特征的学术数据。
一、 主题:关键词抽取主讲人:李稳摘要:这次介绍的两篇文章都是和关键词抽取相关的。第一篇分析了基于统计的和基于图的关键词抽取方法的特点,并发现了一些有趣的结论,并对后续科研人员方法的选择和使用提出了建议。第二篇针对的是学术概念抽取任务,提出了一个简单但有效的无监督方法,目标是自动提取学术文献中的学术概念。时间和地点:3月19日9:00-10:00(星期六上午9点-10点),软件学院办公楼201会议室 腾讯会议 I...
一、 主题:少样本命名实体识别主讲人:吴佳琪摘要:随着预训练语言模型的提出,命名实体识别模型在充足的数据量情况下,具有很好的性能和鲁棒性。但是在现实的应用场景下,构建NER系统仍然是一项劳动密集型、耗时的任务,通常只有非常少量的标记数据可用于新领域,所以如何使得模型在少样本环境下具有良好的鲁棒性是一个具有挑战性的问题。时间和地点:3月12日9:00-10:00(星期六上午9点-10点),软件学院办公楼201会议室 ...
一、 主题:神经与逻辑结合的自然语言推理主讲人:郑威摘要:预训练语言模型在自然语言推理(NLI)任务实现了较高性能,与此同时NLI对符号方法的关注较少。该文章提出一种将深度学习与符号方法结合的系统来解决NLI任务,提出了一个称为 NeuralLog 的推理框架,它利用基于单调性的逻辑推理引擎和神经网络语言模型进行短语对齐,实验表明,其联合逻辑和神经推理的系统提高了NLI任务的准确性。时间和地点:3月5日9:00-10:00(星期六...
一、 主题:深度学习学习资料及经验主讲人:吴佳琪摘要:推荐深度学习相关书籍、视频课程,讨论深度学习方向的学习经验时间和地点:1月7日10:00-11:00(星期五上午10点-11点),腾讯会议地址:922-305-896一、 主题:语义计算实验室课题介绍主讲人:孙宇清摘要:介绍语义计算实验室当前的应用型课题和研究型课题,讲解学生参与课题的方式时间和地点:1月7日10:00-11:00(星期五上午10点-11点),腾讯会议地址:922-305-896图文...