卡内基·梅隆大学(Carneige Mellon University)是一所享誉世界的私立顶级研究型大学,拥有全美顶级的计算机学院,其语言技术研究所(Language Technologies Institute )也是世界顶级自然语言处理研究中心之一。
徐熙同学在大三学年加入语义计算实验室,在孙宇清老师的指导下参与“基于句法知识的无监督文本改写”以及"多样性文本生成"课题,其中“基于句法知识的无监督文本改写”工作被人工智能旗舰会议AAAI 2023录用。
一、 主题:少样本学习的样本顺序敏感性和可控文本生成主讲人:韩雨辰摘要:本次分享的第一篇工作发现了在少样本学习中样本顺序会对性能产生影响。作者采用了语言模型构造探测集探寻性能较好的样本顺序并通过丰富的实验证明了该方法的有效性。本次分享的第二篇工作与可控本文生成有关,在解码阶段将多属性可控的文本生成问题转化为多目标优化问题,使用拉格朗日乘子和基于梯度下降的技术来生成所需的文本。时间和地点:11月30日1...
一、 主题:可控文本生成主讲人:郑璐阳摘要:本次讨论班分享的两篇论文都是和可控文本生成相关的。第一篇论文是设计了一个有效的多属性可控文本生成框架,其中包含的对比生成器、外部判别器和top-n加权解码都可以有效的提升生成文本的质量;第二篇论文则是提出了一个端到端的知识引导的学术论文评论生成框架,其中知识包含两种不同类型的知识,分别是概念图和引用图,模型借助知识可以生成质量更高的论文评价。时间和地点:11月...
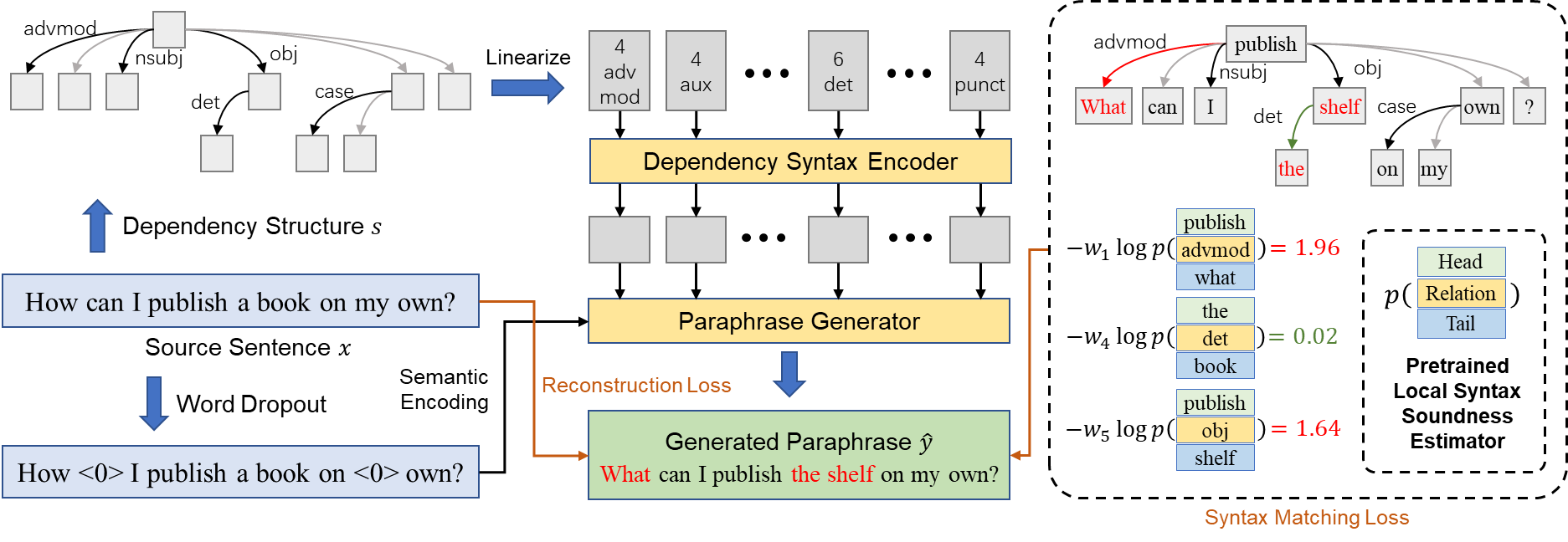
摘要——在文本改写生成任务中,句法的合理性是一个重要的考量。多数现有文本改写方法在使用隐含向量的方式控制句法和语义,无法保证结果的句法合理性。本文中我们探究词汇语用时的句法结构模式形成词汇组合知识,并将之整合到文本改写生成过程中,以显式的方式控制生成内容的句法。该组合知识通过建模词汇间的依存句法关系,形成词汇级句法合理性的估计函数。在文本改写过程中,通过一个层次化的句法结构损失函数,来量化所生成的句子是否满足给定的句法结构,以确保整句级别的句法合理性。以上方式使得生成过程能够正确考虑语义和句法两方面来选择正确的词汇。本文提出的方法在多个改写数据集上进行了测试。实验结果表明本文方法所生成的改写句优于对比方法,在句法正确性上表现尤为突出。
一、 主题:文本哈希与层次化分类主讲人:黄钿摘要:本次分享的第一篇工作主要与文本哈希相关,由于其带来了相似性计算的高效性,文本哈希成为了许多大规模文本检索系统的关键组件。在第一篇工作中,作者采用了对比学习方法并引入ARM估计来构建文本哈希方法,并通过丰富的析构实验来证明了其有效性。本次分享的第二篇工作与层次化分类任务有关,层次化分类任务是一种特殊的多标签任务,该工作的主要思想是将传统的层次分类任务视...